
DALL-E 3的到底有多强大,它所推崇的只需要对话就可以理解用户的用意是怎样的呢?现在我们就来了解一下,打开DALL-E-3在输入框中输入描述点击创建就可以开始使用了,支持中文输入。
案例
众所周知DALL-E 3号称语义理解强者,是目前流行大模型中,能够精准理解用户描述词的唯一大模型,下面我们就来体验一下:
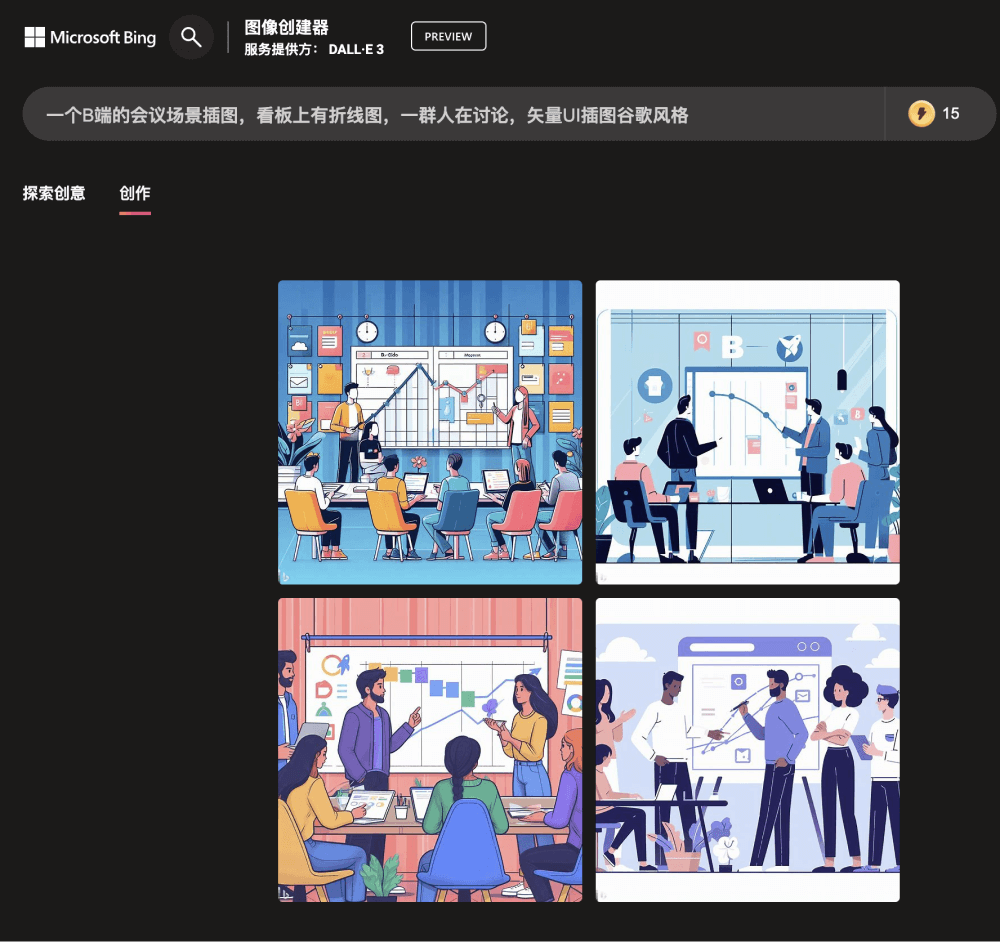
举个例子,我们输入“一个B端的会议场景插图,看板上有折线图,一群人在讨论,矢量UI插图谷歌风格”这样的描述。DALL-E 3可以准确抓取描述中的关键信息如“B端”“会议场景”“看板”“折线图”“讨论”等,合理地布局元素位置,同时运用“谷歌风格”“矢量UI”等细节需求,生成符合语义要求的高质量图像。
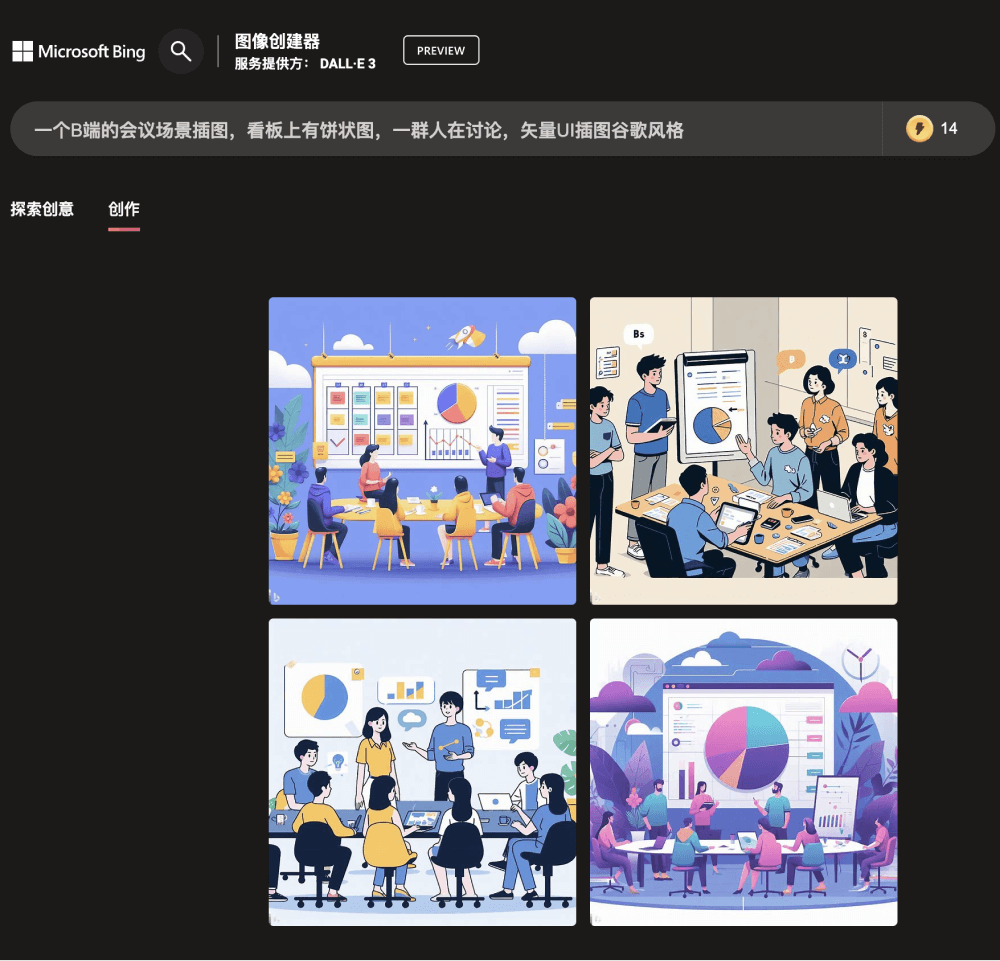
接下来我们将提示词中的折线图改为饼状图,DALL-E 3可以基于细微变化的语义需求,更新生成包含饼状图而不是折线图的新的图像。
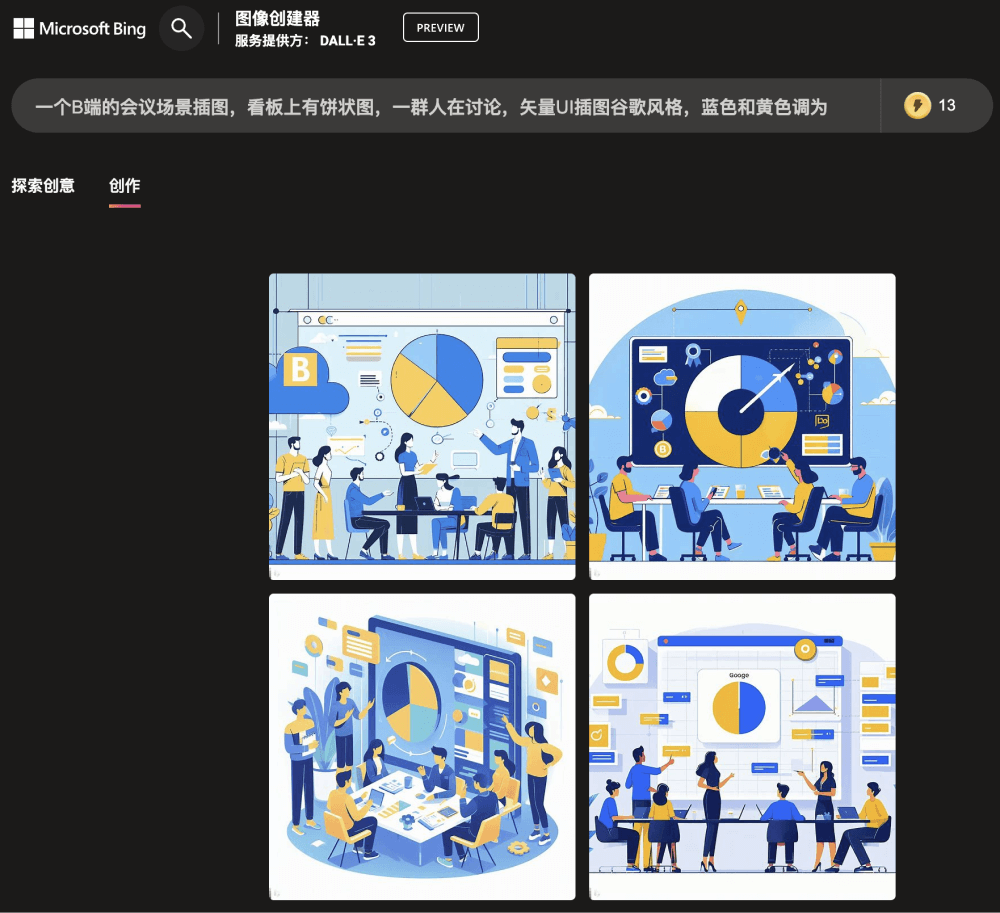
如果进一步指定为蓝色和黄色调为主,DALL-E 3可以精准捕捉到这个色调词生成准确的图像,这展现出它根据描述语言微调,实现风格个性化控制的优势。
DALL-E 3的能力
通过上面的例子可以看出,DALL-E 3具有精确理解描述语义、细节处理和创意风格控制的强大能力。它可以深入挖掘文本信息,转换为高质量的视觉呈现。
除了上面表现出的能力外,DALL-E 3在人物姿态、服饰细节、背景元素等,DALL-E 3生成的图像可以高度还原文本描述的细节要求, DALL-E 3还可以生成不同画风、光照以及情绪氛围的图像,以及可以在图像中准确嵌入英文、数字等文本信息。
用户只需文字描述即可使用,相比其他模型需要去学习各种参数的设定,DALL-E 3的使用更为简单高效。
——————————————————————————
版权声明:此文章来自标记狮社区,转载请附上原文出处链接。
原文链接:https://mmmnote.com/article/7e7/12/article-bf826030d4e6fa57.shtml
版权声明:此文章来自标记狮社区,转载请附上原文出处链接。
原文链接:https://mmmnote.com/article/7e7/12/article-bf826030d4e6fa57.shtml